ニューラルネットワークによる翻訳とは何か?
現在主流の機械翻訳はほとんどがニューラルネットワークによるものだ。ニューラルネットワークがどういうものかは前回説明したけど、それではニューラルネットワークによる翻訳とは一体どういうものなのだろう。
ここでは私なりに理解したことを書いてみる。とはいえ、この説明が本質的に正しいかどうかは実をいうとよくわからないので1、正しく理解したいという人は申し訳ないけど、『ゼロから作るDeep Learning ❷ ―自然言語処理編』を読んでほしい。
10単語の世界
単語数が10個しかない世界を考えてみる。それらの単語に1から9の番号を付ける。それらとは別に文章の終わりを示す句点やピリオドに相当する記号があり、それを0とする。この世界の文章はすべて1〜9の単語+0という組み合わせで作られていることになる。
単語の入力と出力
ある文章をニューラルネットワークに入力する場合、それぞれの単語の入力は、次のように1つの神経細胞に1つの単語を割り当てる形で行えば良いだろう。
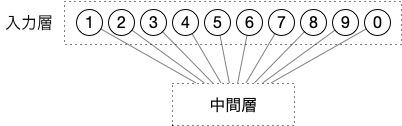
例えば最初の単語が6だった場合は、6の神経細胞を「オン」にする。
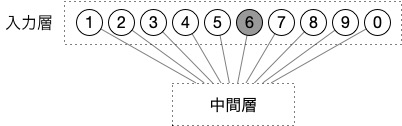
単語の出力も入力と同様に特定の神経細胞を「オン」にすることでどの単語が出力されたかわかるようにする。
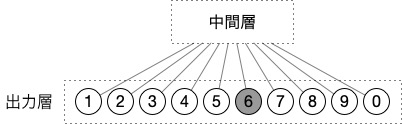
以降の説明では、次のように省略して記載するが、入力層や出力層には上記のような仕組みがあると理解してほしい。
次の単語当てゲーム
最初の単語を入力し、次の単語が何かを予測して出力するようなニューラルネットワークを考えてみる。単語の入力と出力なので図示すると次のようになる。
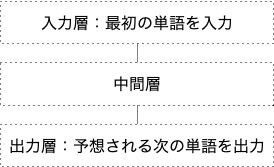
大量の教師データ(調整用データ)を用意し、調整(バックプロパゲーション)すれば、出現頻度の高い単語が出力されるようになるはずだ。
この場合、調整データとなる実際の文章は、全て最後が0で終わる1〜9までの数字の羅列に置き換えられる。例を次に示す。
12959651520
833293140
35194832260
2630
298162192630
実際には1〜9までの数字が当てられている単語があるわけで、その並びには言語である以上規則性があるだろう。ニューラルネットワークの場合は、そういった規則を、大量の教師データを何度も読み込み調整していくことで自身に叩き込むわけである。もちろん、単語1つだけでは、次の単語の予想は間違いも多いだろう。それでは単語2つの場合はどうか。
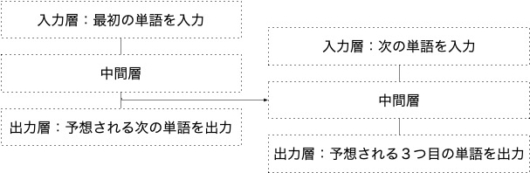
単語1つの場合との違いは、最初の単語の中間層からの出力が次の単語の中間層に入力されていることだ。出力層では、中間層からの出力を元に予想した単語を出力する。この中間層の出力が次の単語の中間層に入ることで、3つ目の単語の予想精度は上がるだろう。
このようにして、文章の終わりを示す句点やピリオドに相当する記号(0)が出てくるまで、次の単語当てゲームを行っていく。
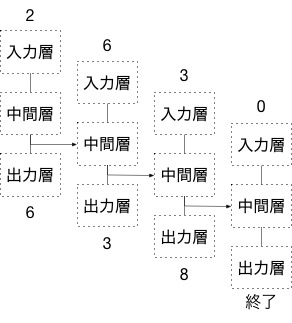
このようにして作られたニューラルネットワークは自動的に文を生成する機械として使うことができる。最初に何らかの単語を入力すると、予想した次の単語が出力される。その単語をさらに次の入力にすれば予想したその次の単語が出力される。この作業を文書の終わりが来るまで行うことで文が生成される。
ただ、この場合は最も確率が高い単語が選択されるため、もう一度同じ単語を入力しても同じ文章が生成されるだけであり面白みにはかけるだろう。そこで、文章に変化をもたらしたい場合は、単語を選択するプロセスを加工する必要がある。
翻訳のためのニューラルネットワークを作る
それでは翻訳のためのニューラルネットワークについて考えてみる。もっとも単純な方法は、前節で説明した次の単語を予想するニューラルネットワークを原語、訳語それぞれに用意し、連結することである。
原語側は前節までで説明した1〜9+0の原語を使うことにし、訳語側も原語と同様の10単語で、それぞれの単語にA〜I+Zを割り振る。そのうち、文章の終わりを示す句点やピリオドに相当する記号をZとする。
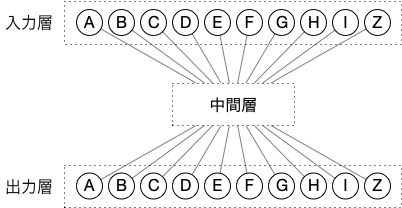
2つのニューラルネットワークを連結すると次のようになる。
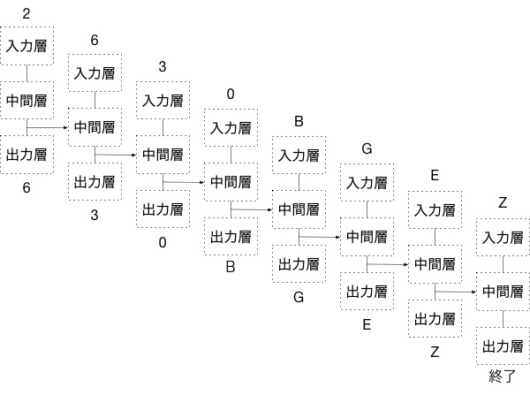
原文が2630、訳文がBGEZで、その2つのニューラルネットワークが接続されている。
この翻訳用のニューラルネットワークの教師データは、原文と訳文の対が並んだものとなる。
| 訳文 | |
|---|---|
| 12959651520 | ABIEIFEAEBZ |
| 833293140 | HCCBICADZ |
| 35194832260 | CEAIDHCBBFZ |
| 2630 | BFCZ |
| 298162192630 | BIHAFBAIBFCZ |
この場合、翻訳を適切に行うためのポイントはどこにあるのだろうか。
一つは原文を元に訳文の最初の単語をうまく予測することだろう。上記の図では、2630が入力された時に、訳文の最初の語としてBを予測できるかどうかが重要だ。それさえできれば、その単語に引き続く訳語については、訳文側の次の単語の予測機能を使うことで生成すればよい。
以上でニューラルネットワークを使った翻訳がどういうものかについての説明は終わりである。
実際に使われているニューラルネットワークによる翻訳システムはこんな単純なものではなく、精度を上げるために様々な機能が付加されている2。もっと詳しいことが知りたい場合は専門書をあたってほしい。
終わりに
ここまでニューラルネットワークを使った翻訳についての私の理解を説明してみたが、ポイントは、ニューラルネットワークは原語の構文や単語の意味を理解しているわけではないことである。あくまでパターンの認識であり、繰り返し入力されるパターンが強化される。ここまで単語に数字やアルファベットを割り振って説明したのは、そのイメージを伝えるためである。
ここまで書いてきて思ったが、統計的機械翻訳もニューラルネットワークもその翻訳手順は似たようなものである。ニューラルネットワークによる翻訳が恐ろしいのは、ニューラルネットワークが人工的な脳のようなものであることに尽きる。統計的機械翻訳では、翻訳するためのプログラムは全て外に見えているが、ニューラルネットワークでは、その部分はブラックボックスである。翻訳に適した脳を構築し、その脳に合わせた教材を使って訓練することで優秀な翻訳脳を作り出すという点がとにかく大きな違いで未来に対して大きく開かれていると思う。
次回は私達が使うことができるニューラルネットワークを使った翻訳サービスの品質についての評価を行ってみたい。